AWS Deep Dives - SQS (Simple Queue Service)
Amazon SQS (Simple Queue Service) is an easy to use and inexpensive way to decouple portions of a serverless application through a secure, cloud-based queueing system. Let's explore how that's useful and how to use it.

My last article in this series covering SES was far more straightforward. It was sufficient to explain what SES does, comfortable in the knowledge that you understood the need for an application to occasionally send emails.
SQS, which stands for Simple Queue Service, does exactly what the name implies: it’s a secure, cloud-based queue. However, it may be far less obvious to you why you may need a queueing system in the first place. Understanding that requires a bit of discussion around serverless architectures.
But to add further confusion to an already potentially confusing topic, there are multiple other services on AWS that satisfy very similar requirements as SQS.
Before this article shows you how to use SQS, it will dive into why you’d need it in the first place and when you’d use it versus other similar AWS services.
Why Do You Need a Queue Service?
A well-architected serverless application has functions that follow the single responsibility principle and services that are loosely coupled. What this terminology means in practice is that my functions are concise and serve a single purpose, making them reusable and easier to maintain, and that services and functions are decoupled. A change to one or a migration to a different service doesn’t require updates across the codebase.
This is easier to understand with an example.
You run a very popular e-commerce site that sells widgets. Everyone needs widgets! Of course, one of the core functions of your system is that it accepts orders from customers. After it is accepted, each submitted order needs to be sent to the order processing system. But, like a good architect, your ordering system and order processing systems are fully decoupled.
For this to work, you need to ensure that each order is processed once and only once, as you don’t want to be fulfilling orders twice. There’s also the possibility that the order processing system is down or cannot be reached for some reason – even with a 99.99% availability on each service, that still means there is a probability (albeit brief) of downtime on each service that you need to account for.
We could catch the error and send an error message back to the user notifying them of the failure, but that’s a terrible experience and likely to result in lost revenue. Plus, our order processing is asynchronous (meaning it doesn’t necessarily happen as soon as the order is placed), so there’s a solid chance the user would never see the error in the first place.
What we need is something to notify the processing service that an order was accepted while ensuring:
- Each order is processed once and only once
- Orders are processed asynchronously
- Even in cases where the processing service is unreachable, orders are not lost – plus we should be notified of any orders that may have failed to be processed due to extended outages or failures.
What we need is a message queue service.
This is just one scenario and one use case for a queue but hopefully it helps to illustrate how a queue can help you create decoupled architectures to increase reliability and reduce failures.
When to Use SQS?
If you’re familiar with AWS services, you may be like, “But SNS can accomplish that! Or EventBridge!” Technically, yes, as each of those services can also pass messages across event-driven architectures. However, there are specific differences between SQS and these services:
- SQS is pull-based while the other services are push-based. This means that subscribers need to poll SQS to get new messages, something that can be done in Lambda or EC2, for instance. This also means that you should choose other services if it is important that messages are received in real-time.
- Messages are guaranteed to be delivered at least once and persist until they are consumed, deleted or expire so that messages are not lost (though duplicate messages are possible). This is an important distinction. While EventBridge and SNS all support at least once delivery, messages do not persist on those services.
- If the order in which messages are processed is important, SQS (and SNS) support first-in-first-out (FIFO) ordering. EventBridge does not have ordering guarantees. For a more detailed reference on the differences and use cases, I suggest reviewing the AWS Decision Guide covering this topic.
Types of SQS Queues
There are several types of queues that you can define in SQS, so let’s take a look at these.
Standard Queue
A standard queue is useful for asynchronous processing where the order in which messages are received isn’t critical. Standard queues use “best-effort” ordering, which means that messages may not always appear in the order in which they were sent.
Below I’ve laid out a standard queue with typical settings using the AWS CDK. Technically speaking, only the name is required to create a queue and, in fact, most of the remaining settings are set to their defaults. The only non-default setting is the receiveMessageWaitTime that is configured to use long-polling, which can help reduce SQS costs. You can read more about short versus long polling in the AWS documentation.
// Create a standard (non-FIFO) SQS queueconst myQueue = new sqs.Queue(this, 'MyStandardQueue', { queueName: 'my-standard-queue', // How long SQS retains a message // Default is 4 days, min is 1 min, and max is 14 days retentionPeriod: cdk.Duration.days(4), // How long a consumer has to process a message before it’s visible again // default is 30 seconds but can be up to 12 hours (43200 seconds) visibilityTimeout: cdk.Duration.seconds(30), // Delay new message availability to consumers (0–15 min, default is 0) // Useful for buffering long running processes delaySeconds: 0, // A number greater than 0 enables long polling which can reduce costs // default is 0 but max is 20 seconds receiveMessageWaitTime: cdk.Duration.seconds(20),});FIFO Queue
In situations where the ordering matters, you’d define a first-in-first-out (FIFO) queue. The only required differences between the standard queue above and the FIFO queue below are the name, which must end in .fifo to make it clearly identifiable, and the fifo setting being set to true.
I’ve also set contentBasedDeduplication to true, which can help prevent potentially duplicate messages by blocking subsequent messages with duplicate content during a five minute interval.
const myFifoQueue = new sqs.Queue(this, 'MyFifoQueue', { // FIFO queues must have names ending with .fifo queueName: 'my-fifo-queue.fifo', // Explicitly mark it as FIFO fifo: true, // During the 5 minute deduplication interval (5 minutes) // SQS treats messages twith identical content as duplicates contentBasedDeduplication: true, visibilityTimeout: cdk.Duration.seconds(30), retentionPeriod: cdk.Duration.days(4), receiveMessageWaitTime: cdk.Duration.seconds(20), delaySeconds: 0,});Dead-letter Queue (DLQ)
A dead-letter queue is a queue that is used to retain messages that failed after a specified number of retries. This can be important in situations where failed messages are critical. Using our example above, if an order failed to process, you would want some record of that to investigate and correct the failure.
A DLQ is essentially just another queue, but the DLQ must be of the same type as the queue it is connected to – a standard queue must have a standard DLQ and a FIFO queue must have a FIFO DLQ. The example below shows the same FIFO queue defined in the prior example, but with the DLQ queue specified in the deadLetterQueue settings to receive any messages that fail after five retries.
const dlq = new sqs.Queue(this, 'MyFifoDlq', { queueName: 'my-fifo-dlq.fifo', fifo: true, // keep failed messages longer for analysis retentionPeriod: cdk.Duration.days(14), contentBasedDeduplication: true,});
// Add DLQ configuration to the prior FIFO queueconst myFifoQueue = new sqs.Queue(this, 'MyFifoQueue', { queueName: 'my-fifo-queue.fifo', fifo: true, contentBasedDeduplication: true, visibilityTimeout: cdk.Duration.seconds(30), retentionPeriod: cdk.Duration.days(4), receiveMessageWaitTime: cdk.Duration.seconds(20), delaySeconds: 0, deadLetterQueue: { // after 5 failed receives, message goes to DLQ maxReceiveCount: 5, // use the previously defined queue as the DLQ queue: dlq, },});While it’s beyond of the scope of this article, SQS also supports DLQ redrive, which allows you to move items off the DLQ to be reprocessed.
SQS Costs
As AWS services go, SQS pricing is not only pretty straightforward but also, in my opinion, relatively inexpensive. The most important part is that if you’re new to SQS and curious to try it out, the first one million requests per month are free, regardless of whether you are using a standard queue or a FIFO queue.
It’s worth pointing out that one request, in the context of pricing, is not the same as one message. A single request can include up to 10 messages with a maximum total payload of 1 MiB (mebibyte). This is where long polling can potentially decrease your costs.
Once you exceed one million requests, the cost depends on whether you’re using a standard queue or a FIFO queue. In the us-east-1 region, for example, a standard queue costs $0.40 per million requests (up to 100 billion requests per month), while a FIFO queue costs $0.50 per million. Pricing may vary depending on the region you’re deploying to, as well as other factors.
Using SQS
Let’s take a quick look at how to use SQS in a simple example. This example simulates an ordering system wherein a order is received by the order management API that would make sure the order is correctly stored, charged and, once accepted, added to the order processing queue. The order processing backend watches for order items on the processing queue and handles making sure orders are fulfilled. We’ll focus only on the portions of the code related to SQS usage.
Defining SQS Resources
We’re creating a number of resources in our CDK script, so let’s focus on the specifics around SQS. First, we need to define two queues, the DLQ that will contain any messages that fail by the defined number of retries. We’ve set it up to retain these records for 14 days to give us time to investigate failures.
We’ll pass this DLQ as a property of the main FIFO queue, which only has a 4 day retention policy and has deduplication turned on to prevent accidentally processing the same item twice.
// Dead Letter Queue (DLQ) holds messages that have failed processing after maximum retriesconst dlq = new sqs.Queue(this, 'DeadLetterQueue', { queueName: 'sqs-dlq.fifo', fifo: true, contentBasedDeduplication: true, visibilityTimeout: cdk.Duration.seconds(30), retentionPeriod: cdk.Duration.days(14),});
// Main FIFO SQS Queueconst queue = new sqs.Queue(this, 'OrdersFifoQueue', { queueName: 'sqs-main-queue.fifo', fifo: true, contentBasedDeduplication: false, // we're passing a deduplication id to the queue visibilityTimeout: cdk.Duration.seconds(30), retentionPeriod: cdk.Duration.days(4), deadLetterQueue: { queue: dlq, maxReceiveCount: 3, },});Our orderManager Lambda function writes to the SQS queue, so we’ll need to add permission to enable that.
queue.grantSendMessages(orderManagerFunction);The orderProcessor function consumes messages from the main FIFO queue while the dlqProcessor reads items that end up on the DLQ, so we’ll add those permissions as well.
queue.grantConsumeMessages(orderProcessorFunction);dlq.grantConsumeMessages(dlqProcessorFunction);Next, we need to define our event source mapping to connect our SQS queue to our Lambda functions. For the order processing queue, we’re passing only one item at a time. We could batch items, which would save costs, but it’s important to remember that any error will send the entire batch back. For example, if we processed all the items in an order as a batch, if one item fails, all the items will be put back in the queue. In our case, as we’ll discuss later, we’ve designed the system to fail on at least one item as a way to demonstrate retries and the DLQ. This means that if we batched them every item in the order would eventually end up on the DLQ rather than just the single failed item.
orderProcessorFunction.addEventSource(new lambdaEventSources.SqsEventSource(queue, { batchSize: 1, // Process one message at a time}));
dlqProcessorFunction.addEventSource(new lambdaEventSources.SqsEventSource(dlq, { batchSize: 10, // Process up to 10 messages at once}));We can deploy this stack to LocalStack using cdklocal, which is a this wrapper for the AWS CDK.
cdklocal bootstrapcdklocal deployWe can then use awslocal (another thin wrapper around the AWS CLI) or the LocalStack web app to interact with the deployed resources.
Adding Items to the Queue
Let’s look at the main orderManager handler function that will add accepted order items to the main FIFO queue.
First off—while unrelated to SQS—we don’t want to accidentally accept duplicate orders, so we’ve made our function idempotent using the AWS Lambda Powertools idempotency library. This automatically ignores duplicate events with the same payload received by the handler, returning the previous result. (Note: we’re also using the Powertools library for structured logging.)
Once the items have been accepted (in this example, they’re simply added to the appropriate databases) we send a message for each item to the queue. Our processor (as we’ll see) processes each item individually rather than treating the entire order as a single unit. The message body contains details about the item in the order, which we can later use when the SQS messages are consumed by the processor.
// we're using Lambda Powertools idempotency to prevent duplicate orders from being submittedexport const handler = makeIdempotent( async (event: OrderEvent, _context: Context): Promise<APIGatewayProxyResult> => { const orderItems = event.orderItems; const orderId = event.orderId; const userId = event.userId; const orderStatus = event.orderStatus;
// a real world application would probably process payment here // but for this example we'll just add the order to the database const orderItemRecords = await addOrderToDatabase(orderId, userId, orderItems, orderStatus);
logger.info(`Adding order items to DynamoDB for order ${orderId}`); logger.info(`Order items: ${JSON.stringify(orderItems)}`);
// Send each item as a separate message for individual processing const messagePromises = orderItemRecords.map((itemMessage, index) => sqs.send(new SendMessageCommand({ QueueUrl: process.env.ORDERS_FIFO_QUEUE_URL as string, MessageBody: JSON.stringify(itemMessage), MessageGroupId: itemMessage.orderId, MessageDeduplicationId: `${itemMessage.itemId}-${Date.now()}-${index}`, })) );
await Promise.all(messagePromises); return { statusCode: 200, body: JSON.stringify({ message: 'Orders processed successfully' }) }; }, { persistenceStore,});Consuming Items from the FIFO Queue
As we saw in our event source mapping defined in the CDK, the orderProcessor listens to the main SQS FIFO queue. When items are on that queue, the Lambda will be triggered to process them.
export const handler = async (event: SQSEvent, context: Context): Promise<void> => { logger.info(`Processing ${event.Records.length} messages`);
// SQS can batch messages, but one error will cause the entire batch to fail // so we're processing each message individually since we're simulating failures await Promise.all( event.Records.map(record => processRecord(record)) ); logger.info(`Successfully processed all ${event.Records.length} messages`);};If this were a real order processing system, we’d trigger a fulfillment of the order item passed with each SQS message, but, for the sake of example, we’re just simulating processing by updating the record in the database.
In order to simulate retries and the DLQ, our processing has some code that will cause items with a itemId ending in 1 to fail 50% of the time. This means that if they fail the first time, they will likely succeed on a successive retry. Items with an itemId ending in 3 will fail every time, which means they will always end up on the DLQ.
Consuming Messages from the DLQ
The event source mapping triggers the dlqProcessor whenever an item ends up on the DLQ. A DLQ is just another queue, so there’s no difference in how you consume it, as you can see below:
export const handler = async (event: SQSEvent, context: Context): Promise<void> => { logger.info(`Processing ${event.Records.length} DLQ messages`);
// Process all DLQ messages await Promise.allSettled( event.Records.map(record => processDLQRecord(record)) ); logger.info(`DLQ processing complete for ${event.Records.length} messages`);};The main difference is what you do with that data. In our example, we’re just marking items as failed, but in a real world application, you might do other things like use SNS to notify someone internally of the failure which might trigger a process for review of some sort. Since this is an ordering system, you might also use SES to notify the customer that the order failed and customer service has been notified and will reach out. Remember, since the whole process is asynchronous, the frontend of this ordering application would not have notified the customer of the failure when the order was submitted and accepted.
Testing the Example
Assuming the resources are deployed to LocalStack already, I’ve provided a simple command as well as some sample data to test the processing of the queue.
You can go to the LocalStack web app and invoke the orderManager Lambda (you can easily paste in the JSON as a payload) or I’ve provided a shortcut for invoking it via the command line.
make test-orderIf we head into the LocalStack web app resource browser and check SQS for the main FIFO queue, we should see the messages that were added to the queue by triggering the Lambda.
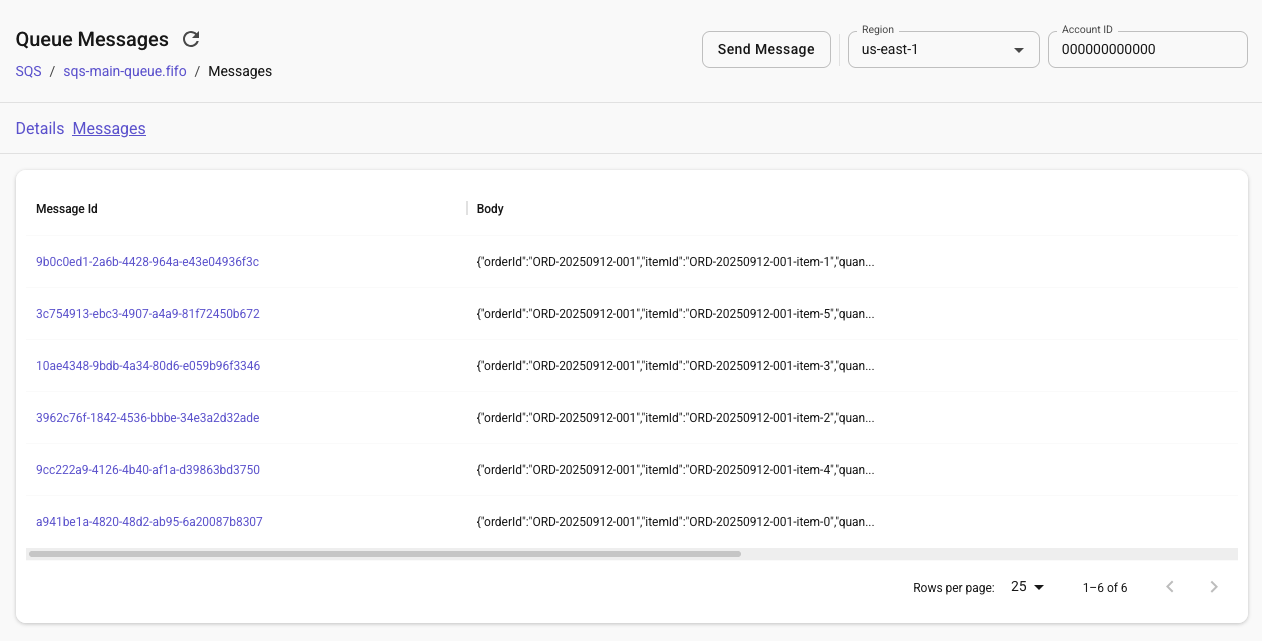
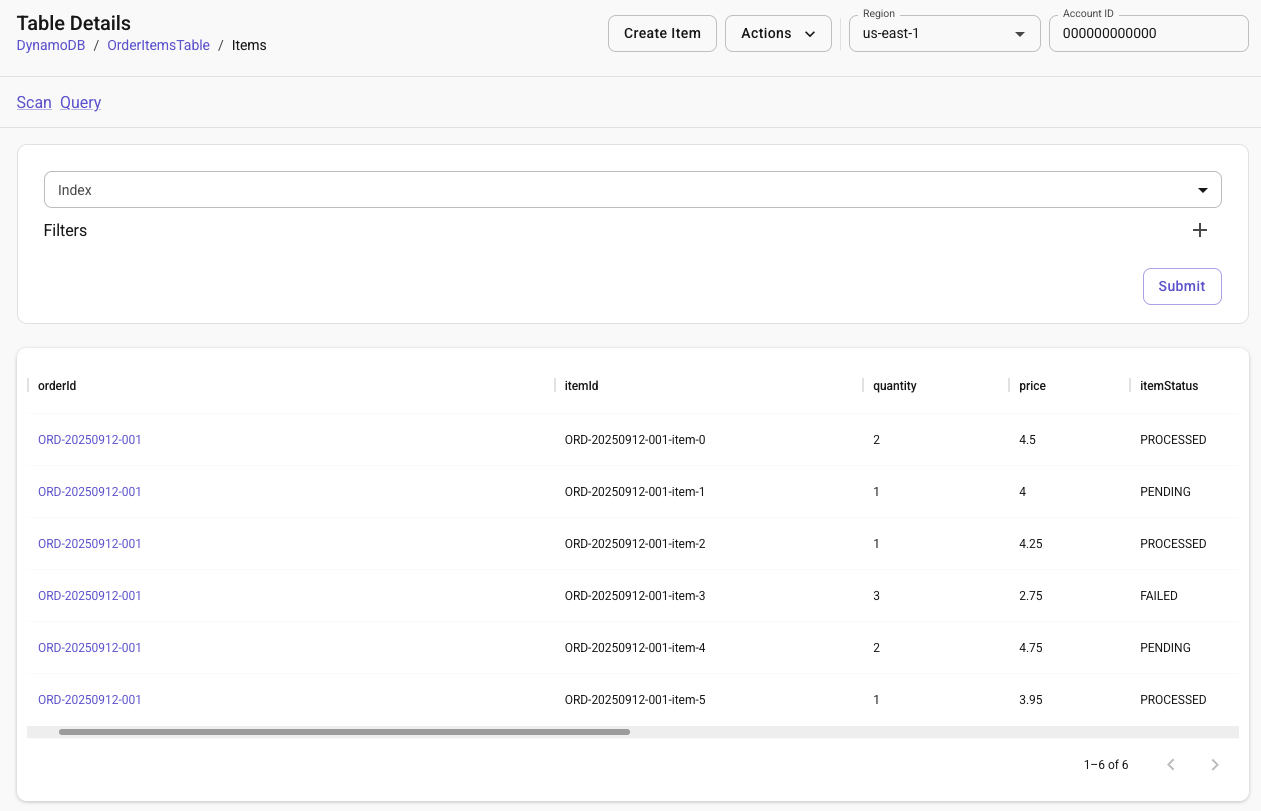
Heading into the DynamoDB order items table, we’ll see the list of items and as each processes, retries or ultimately fails. If we refresh, we can see the status update until it is finally complete. It’s important to reiterate that the demo is designed to have one item potentially forced to have retries and at least one will ultimately fail.
Example Repository
We only explored portions of the code here, but I’ve published the complete example to allow you to test them yourself using the CDK to deploy to LocalStack. You can view the file and instructions on usage at GitHub.
LocalStack Support
I’ve got great news. Not only does LocalStack include 100% API coverage on SQS, but it is also included in our community (open source) image that you can use for free. This includes support for standard queues, FIFO queues, and DLQ (including redrive). You can read more and see the full API coverage in our SQS documentation.
In fact, LocalStack provides debugging capabilities for SQS that you can’t get elsewhere. LocalStack allows you to peek into SQS queues to see without triggering side effects like altering visibility and metrics or triggering timeouts by starting a message’s visibility timer.
Additional Resources
I hope you found this introduction helpful. If you are looking to learn more about SQS, here are official documentation resources and other blog posts that you may find useful.
- What is Amazon Simple Queue Service? - Amazon Simple Queue Service (AWS Documentation)
- Getting started with Amazon SQS - Amazon Simple Queue Service (AWS Documentation)
- Peeking into SQS Queues Locally with LocalStack’s SQS Developer Endpoint (LocalStack blog)
- Complete Guide to AWS SQS: Pros/Cons, Getting Started and Pro Tips (Lumigo blog)
- Amazon Simple Queue Service (SQS): A Comprehensive Tutorial (DataCamp blog)



