Simulating AWS Outages Locally with Chaos Engineering
When AWS goes down, will your app stay up? In this tutorial, we’ll use LocalStack’s Chaos API to simulate real-world AWS service outages including DynamoDB throttling, SQS 503 errors, and Lambda latency so you can test your system’s resilience before production ever feels the heat.

Cloud outages don’t happen often but when they do, they can be brutal.
Recently, an AWS DNS failure in us-east-1 caused a cascade of service disruptions, knocking out DynamoDB, Network Load Balancers, and dozens of applications downstream. It was a painful reminder that no cloud is invincible.
Not every outage is that significant, but even smaller stumbles like a service being temporarily unavailable or just a dropped request can potentially cause problems. Is your application set up to be resilient when it encounters these scenarios?
With LocalStack’s Chaos API, you don’t have to wonder. You can simulate outages across key services like DynamoDB, SQS, and Lambda all within your local environment, without risking production or burning cloud credits.
In this post, we’ll walk through how to:
- Emulate critical AWS services locally
- Inject common failure scenarios using the Chaos API or Web UI
- Monitor how your app responds to throttling, latency, and 503 service errors
- Validate that your retry logic, error handling, and observability stack are actually doing their job
You’ll simulate the same types of failures that made headlines, but in a way that’s repeatable, safe, and fast.
Let’s break some stuff. On purpose!
WTH Is Chaos Engineering?
Chaos engineering is the practice of injecting controlled failures into your system so you can study how it behaves under stress.
It’s not about causing mayhem. It’s about building confidence.
- Does your retry logic actually work?
- What happens when a service times out?
- Does your app gracefully degrade, or just throw a stack trace and give up?
- What happens if an entire region is unavailable?
Better to find out now than during a real production fire drill. Systems go down or are unreachable, that’s an unavoidable part of building applications, even in the cloud. Using chaos engineering can make your app more resilient to failures and chaos testing locally let’s you build that resilience without the risk.
What You’ll Be Breaking
We’re using the same inventory app from the last few posts. Here’s a quick reminder of the flow:
- Suppliers upload a CSV to S3
- A Lambda reads the file and pushes messages to SQS
- Another Lambda reads from SQS and updates DynamoDB
In this post, you’ll inject chaos into:
- DynamoDB to randomly inject
ProvisionedThroughputExceededExceptionerrors to simulate a throttled database, - SQS to force the service to return
503 Service Unavailableresponses, - Lambda to add artificial latency to simulate cold starts or heavy load.
What You’ll Need
- LocalStack installed and running
- A deployed stack using the inventory pipeline repo
- Access to the LocalStack Web UI
Step 1: Open the Chaos Dashboard
Make sure LocalStack is up and running on your machine with your auth token.
Then go to app.localstack.cloud and sign in with your LocalStack account.
Once you’re in:
- Select your local instance
- Click the Chaos Engineering tab
- You’re now ready to start breaking things (safely)
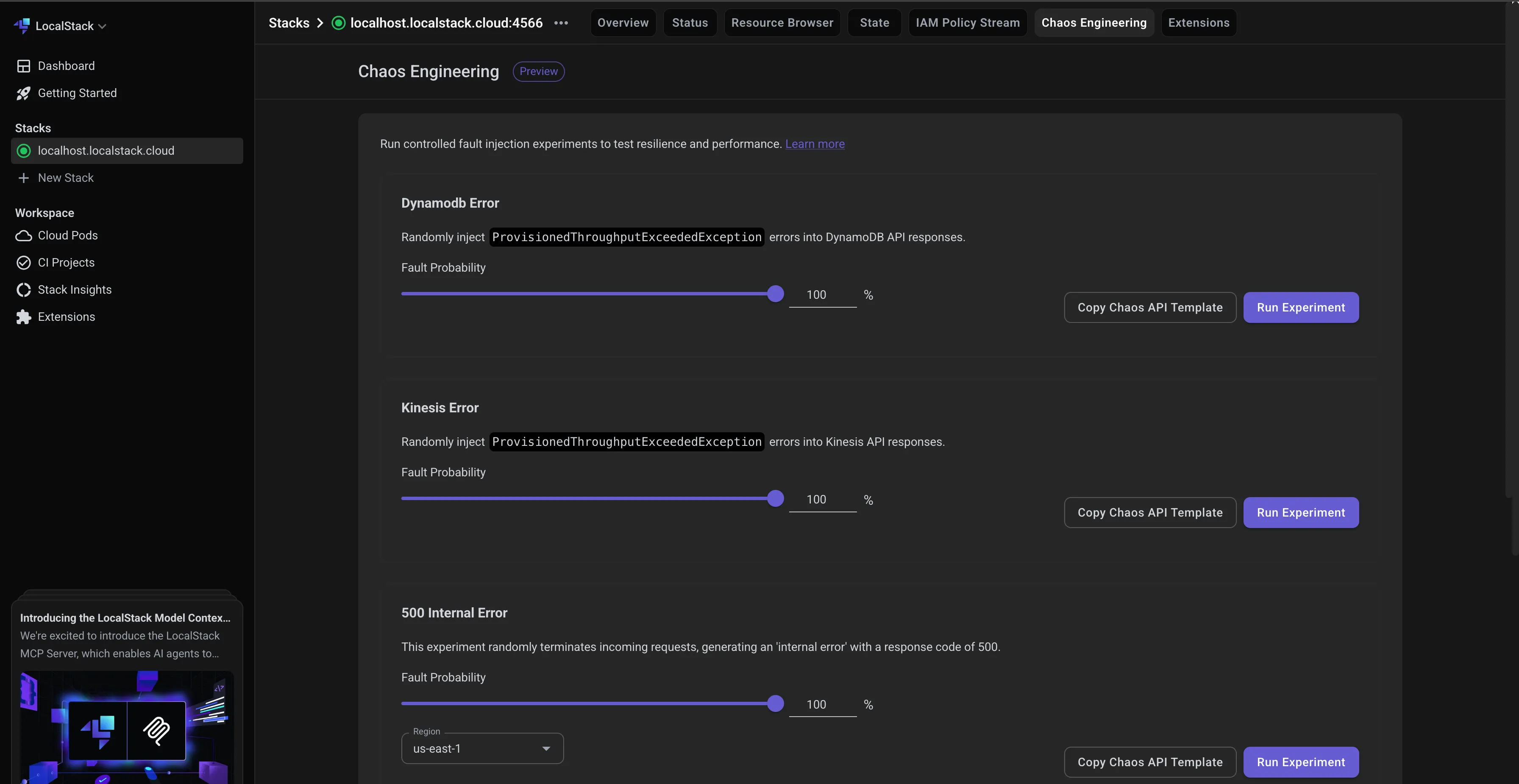
Step 2: Inject Chaos into DynamoDB
From the Chaos Dashboard:
- Select the
Dynamodb Errorfailure type - Set
Fault Probabilityto100% - Click Run Experiment
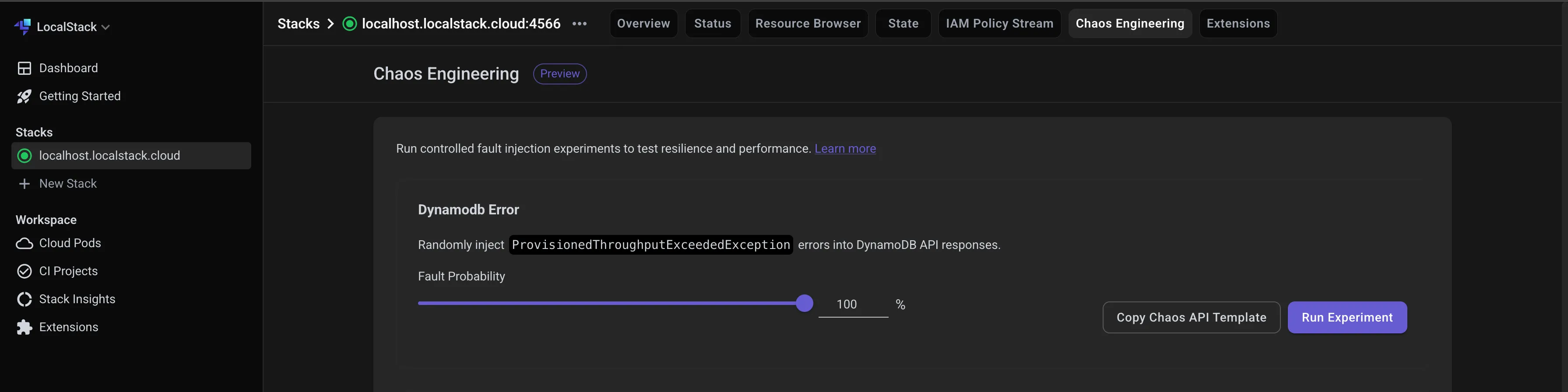
This will randomly inject ProvisionedThroughputExceededException errors into your DynamoDB API responses, the kind of error you’d normally see if your table was under heavy load or had too little capacity provisioned.
Now trigger your app pipeline by uploading a new CSV:
awslocal s3 cp sample.csv s3://<your-bucket-name>/Optional: Inject Chaos via API (curl)
Prefer the CLI? You can also start an experiment using a curl command against the LocalStack HTTP API:
curl -s -X POST 'http://localhost:4566/_localstack/chaos/faults' \ -H 'Content-Type: application/json' \ -d '[ { "service": "dynamodb", "probability": 1, "operation": "GetItem", "description": "dynamodbError", "error": { "statusCode": 400, "code": "ProvisionedThroughputExceededException" } } ]' | jqThis gives you the same behavior as the dashboard, but scriptable and great for pipelines.
Step 3: Watch the Fallout
While the chaos experiment is active, try scanning your DynamoDB table again:
awslocal dynamodb scan --table-name <your-table-name>You should see an error that looks like:
An error occurred (ProvisionedThroughputExceededException) when calling the Scan operation (reached max retries: 2): Operation failed due to a simulated faultThat message means the chaos experiment is working exactly as intended and LocalStack is simulating a throttled database under load. This is your chance to observe how your app reacts when it hits throughput limits. Look for:
- Retries: Does your app automatically try again?
- Failures: Does it crash, timeout, or silently fail?
- Fallbacks: Are you using exponential backoff or circuit breakers?
- Logging: Is the error logged clearly so you’d notice it in a real system?
If everything falls apart, don’t sweat it, that’s the point of chaos engineering. Better to break it here than in production 😅.
Step 4: Try Other Failure Scenarios
Break SQS
Next up, let’s see what happens when SQS itself goes down. We’ll do this using the Service Unavailable experiment in the Chaos Dashboard. When you find it, use the dropdown to select SQS from the list of services and select the region that you’re currently using.
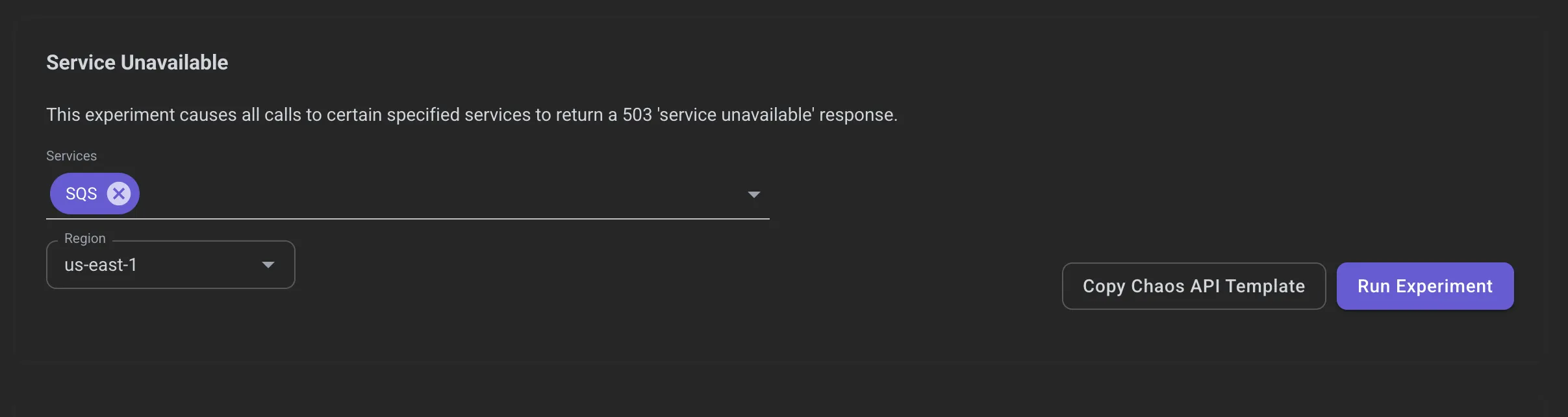
Now trigger your pipeline again by uploading another CSV:
awslocal s3 cp sample.csv s3://<your-bucket-name>/This is what the error you get should look like:
upload failed: sqs_blog/new_sample_file.csv to s3://sqsblogstack-inventoryupdatesbucketfe-dcb5ff0f/sample_file.csv An error occurred (ServiceUnavailable) when calling the PutObject operation (reached max retries: 2): Operation failed due to a simulated faultWhile SQS is down, your Lambda that tries to enqueue messages may fail. This is a good time to observe:
- Do you log the failure?
- Do you retry?
- Does the app give up entirely?
Slooooow Down Lambda
Let’s slow things down. In the real world, Lambda cold starts, memory pressure, or VPC configuration can make functions lag.
Back to the Chaos Dashboard! Last time, I promise. This time we’ll use the Latency experiment. We’ll set latency to something dramatic, like 5000 (or 5 seconds) and then run the experiment.
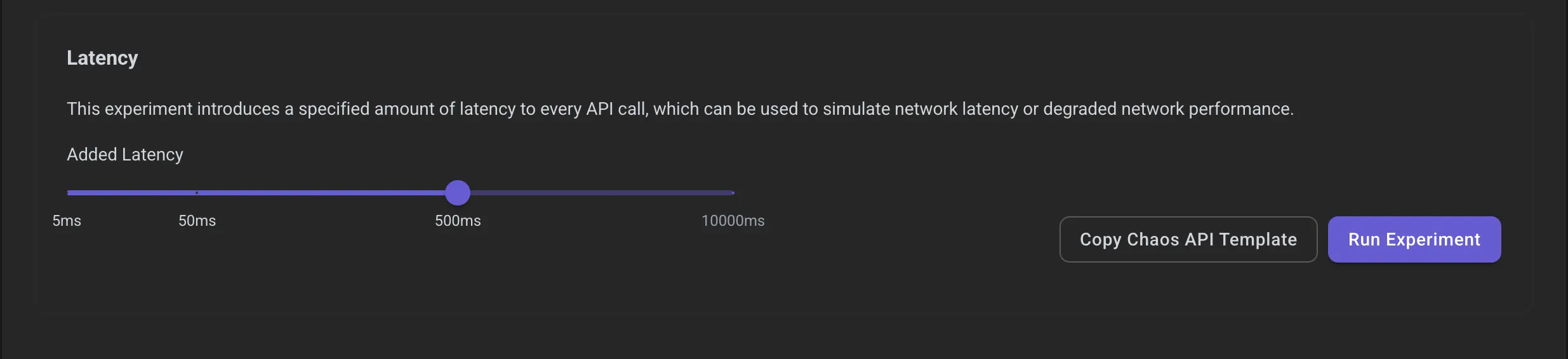
Upload another CSV and watch what happens:
- Does the SQS-to-DynamoDB pipeline slow down?
- Does anything timeout?
- How do you monitor slow Lambdas in dev?
Clean Up and Restore
When you’re done playing chaos monkey, stop the experiments in the dashboard. And if you saved a Cloud Pod beforehand, you can bring everything back with:
localstack pod load my-pod-nameClean. Consistent. No redeploy required.
Resilience Isn’t a Guessing Game
Running AWS locally is great for development. But chaos engineering helps you go further. It helps you build real confidence.
You get to:
- Validate your fallbacks
- Stress-test your messaging flows
- Learn what actually breaks when things go sideways
All without touching production.
You Made It to the End (Without Melting Anything)
Congrats! You didn’t just build a local-first serverless app. You tested it. You automated it. You saved it to a Cloud Pod. And now, you’ve broken it on purpose to make it stronger.
That’s the full arc.
By using LocalStack, you created a repeatable, fast, zero-surprises cloud workflow right on your laptop and you proved it can handle real-world failures without needing real-world outages.
This was the final post in the series, but hopefully the beginning of a new local-first development habit.
Want to revisit any part of the journey? Catch the full companion video playlist on YouTube
Now go forth. Build cool stuff. And if you break it… break it like a professional.



