Why I Run My AWS Serverless Apps Locally First (and You Probably Should Too)
Tired of waiting on CloudFormation, racking up bills, and debugging invisible resources? Learn how to run a real serverless app (S3, Lambda, SQS, and DynamoDB) entirely on your laptop using LocalStack, with step-by-step commands and explanations.

Building serverless apps on AWS is magical. At least that’s what the keynote slides say.
In reality? You push your code, then you wait… and wait… and wait some more while CloudFormation spins up an entire data center. Then you check your AWS bill and wonder, “How did testing cost me $67?” And debugging? Nothing like playing hide-and-seek with resources you can’t even find in the console.
After a few rounds of that, I realized something. Maybe there’s a better way to build serverless apps than repeatedly lighting money and time on fire.
So now, I run everything locally first. I get instant feedback, zero AWS charges, and I actually understand what’s happening. And you can too. Let me show you how.
The App We’ll Run: Real-Time Inventory Management
We’re going to deploy a real-world serverless app on your laptop. It’s an inventory management system that keeps product counts accurate across warehouses, stores, and suppliers, even when everyone is uploading updates at the same time.

Here’s the flow:
- 📄 Someone uploads a CSV file of inventory updates.
- 📦 That file lands in S3.
- ⚡ A Lambda function reads the file and splits it into records.
- 📬 The records get sent to an SQS queue.
- ⚡ Another Lambda function reads the queue and updates DynamoDB.
Basically, it’s like an assembly line for CSVs. But serverless.
What’s Actually Happening Here?
If you’re thinking “Wait, what do all these AWS services actually do?” good question. Let’s walk through them.
S3: The Infinite Filing Cabinet
S3 (Simple Storage Service) is AWS’s answer to “where do I put my stuff?”. It’s a big, reliable, scalable folder in the cloud. You upload files into buckets, and S3 keeps them safe. In this app, S3 holds the uploaded CSV files. Thanks to LocalStack, we can emulate S3 locally. You still upload files, but your cloud bill stays at $0.00.
Lambda: Your Code, Their Problem
Lambda lets you run code without worrying about servers, which is great because you probably don’t want to be woken up at 2 AM because a box ran out of disk space.
In this app:
- Lambda #1 is triggered when a CSV hits S3. It parses the file and sends records to SQS.
- Lambda #2 reads messages from SQS and updates DynamoDB.
All of this happens without you provisioning a single EC2 instance. Pretty neat.
SQS: A Line for Your Messages
SQS (Simple Queue Service) is basically a very patient line at the DMV for your messages. Producers send messages to the queue. Consumers (like our second Lambda) process them when they’re ready. This keeps the system from collapsing when a warehouse decides to upload 37GB of CSVs at once.
DynamoDB: NoSQL, No Worries
DynamoDB is AWS’s fast and flexible NoSQL database. You don’t need to create schemas, worry about connections, or learn what an index is (ok, you should, but DynamoDB is forgiving). Every inventory update ends up here as an item. You can query it instantly, and it just works. Even when running locally with LocalStack.
Setting It All Up
Here’s how to deploy and run the app step by step. You can even do it while drinking coffee and judging AWS’s UX choices.
1️⃣ Clone the Project
git clone https://github.com/aws-samples/amazon-sqs-best-practices-cdk.gitcd amazon-sqs-best-practices-cdk2️⃣ Set Up Your Python Environment
python3 -m venv .venvpip install -r requirements.txtThis gives you a clean virtual environment. Because no one wants to debug a dependency conflict on a Tuesday morning.
3️⃣ Synthesize the Template
cdklocal synthThis generates the CloudFormation template, which is like AWS’s IKEA instructions, except you don’t have to wait two hours for someone to find the Allen wrench.
4️⃣ Bootstrap and Deploy
cdklocal bootstrapcdklocal deployThis kicks off the local deployment. LocalStack spins up your entire stack including S3, Lambda, SQS, and DynamoDBon your machine using the CDK template you synthesized earlier.
While it’s deploying, you’ll see a stream of logs scroll by. Sit back, sip your coffee, and watch your fake cloud come to life. When it finishes, CDK will print out something like this:
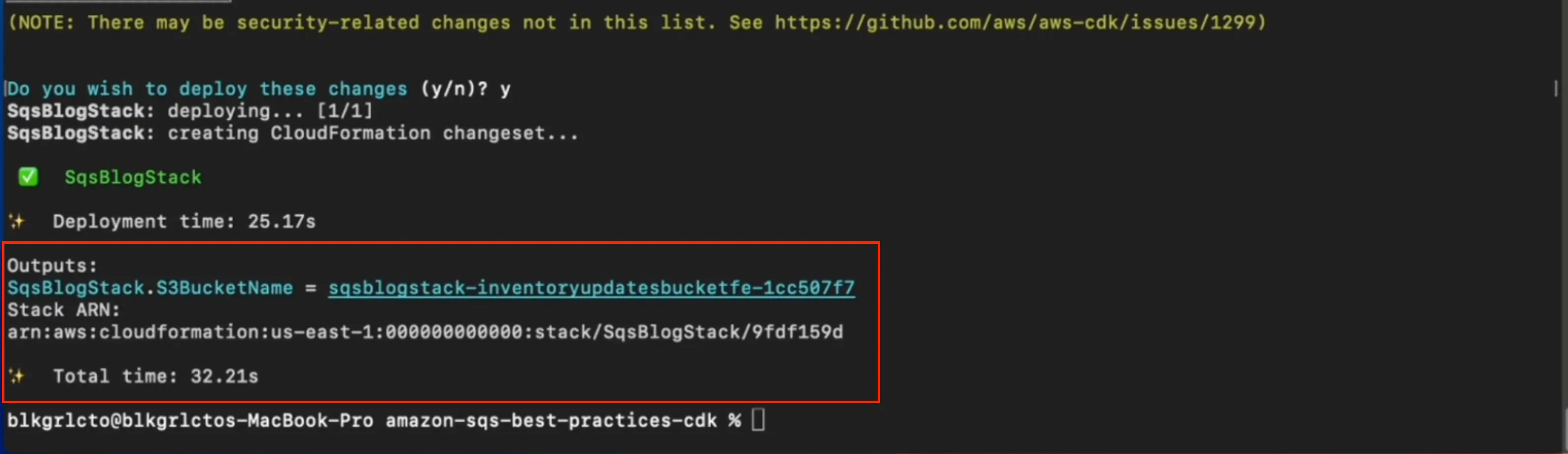
Focus on the Outputs section. This is where CDK tells you the actual names of the resources it just created.
5️⃣ Test the Pipeline
Upload the Sample CSV
Now that your stack is up and running locally, let’s kick off the pipeline by uploading a sample file to S3. Run the following command, but make sure to replace <your-bucket-name> with the actual bucket name from your CDK output in Step 4.
awslocal s3 cp sample.csv s3://<your-bucket-name>/If you forget to update the name, S3 will remind you with an angry error message that sounds like it’s your fault (it is, a little bit). Once uploaded, you can check the LocalStack Web UI or list the contents of your bucket to confirm the file is there:
awslocal s3 ls s3://<your-bucket-name>/If you see inventory records, congratulations. You just ran a full AWS serverless app locally without melting your credit card.
Scan the DynamoDB Table
You’ll need the full table name to scan DynamoDB, but the CDK output doesn’t include it by default. So here’s the move:
- List all DynamoDB tables created by the stack:
awslocal dynamodb list-tables- Look for a table that starts with something like:
SqsBlogStack-InventoryUpdatesIt might have a long suffix, such as:
SqsBlogStack-InventoryUpdatesTableFD7E2601-CYI3W- Once you spot it, plug the full name into the scan command:
awslocal dynamodb scan --table-name <your-table-name>If you see a list of items, congrats. Your whole serverless pipeline just ran locally, from file upload to database write, and you didn’t even touch the real cloud.
If the table is empty, give it a few seconds and try again. Or check the logs in the LocalStack Web UI to see what’s up. Debugging locally is still debugging, but it’s faster, cheaper, and quieter.
What are awslocal and cdklocal?
Glad you asked. When you use the AWS CLI or CDK, they point to AWS by default. Which is awkward when you’re trying to run things locally. So these two tools save the day:
awslocal
Wraps the AWS CLI so that it points to LocalStack by default… instead of typing a mile of --endpoint-url flags, you just run:
awslocal s3 ls…and it talks to your local environment.
cdklocal
Same idea, but for the CDK. When you run…
cdklocal deploy…it deploys your stack to LocalStack instead of AWS.
Why Bother Running Locally?
Here’s the deal.
- You don’t wait 10 minutes every time you deploy a stack.
- You don’t rack up surprise charges.
- You don’t have to play “where did my Lambda go?” in the AWS console.
You get fast feedback and peace of mind, and you actually ensure your app works as expected before shipping it to production.
Quick Reference: All the Commands
# Clone the appgit clone https://github.com/localstack/samples.gitcd samples/aws-cdk-inventory-app
# Set up virtual environmentpython3 -m venv .venvsource .venv/bin/activatepip install -r requirements.txt
# Synthesize templatecdklocal synth
# Bootstrap and deploycdklocal bootstrapcdklocal deploy
# Upload sample CSVawslocal s3 cp sqs_blog/sample_file.csv s3://<your-bucket-name>/
# Check DynamoDBawslocal dynamodb scan --table-name <your-table-name>Running AWS locally is like having a sandbox where you can break things without consequences. It’s faster, cheaper, and way less stressful than breaking the build in your shared development/staging environment or, even worse, debugging production at 2 AM.
🎥 Want to see the full pipeline in action? Check out the video.
In the next post, we’ll write automated tests for this app so it’s even more reliable. Until then, go forth and deploy…locally 😁.



